_2-01.png)

Microsoft Fabric vorgestellt

Überblick über Microsoft Fabric

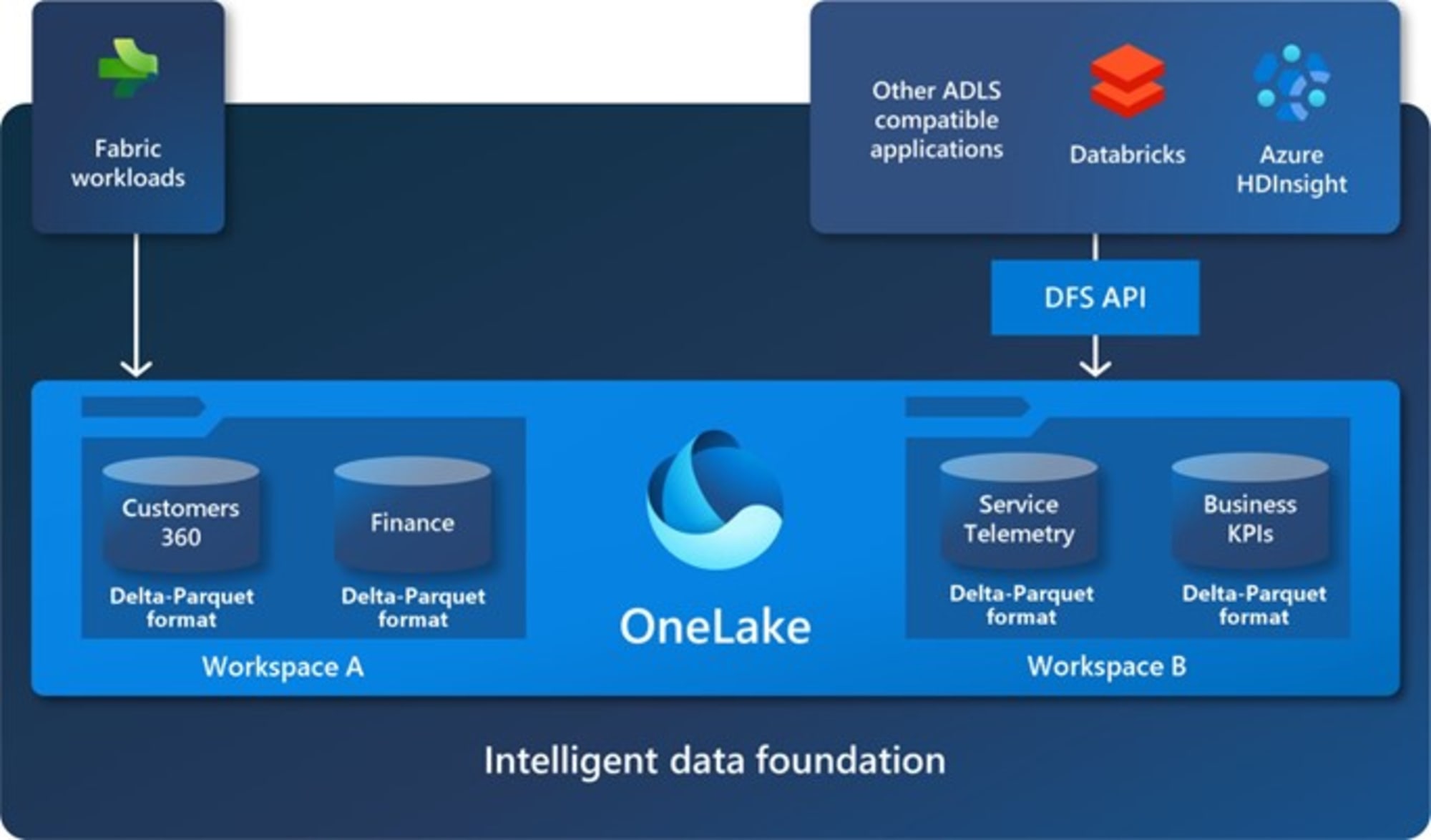
OneLake: Das Herzstück von Fabric

OneCopy: Nur noch ein Datensatz
OneLake vs. Lakehouse vs. Data Warehouse vs. Delta Lake (Tables)
Die unterschiedlichen Begriffe im Zusammenhang mit Fabric können zu Verwirrung führen. Im folgenden Abschnitt werden daher die geläufigsten Benennungen gegenübergestellt.
Zusammenfassung (tl;dr):
OneLake: Der zentrale Speicherort für Lakehouses und Data Warehouses.
Lakehouse:
Vereint die Funktionalitäten eines Data Lakes und eines klassischen Warehouses.
Fokus auf Spark.
Stellt einen Read-Only SQL Endpoint zur Verfügung.
Data Warehouse:
Fokus auf SQL.
Unterstützt DDL- und DML-Abfragen.
Delta Lake: Das verwendete Format von Objekten im OneLake.
OneLake
Wie in einem vorherigen Abschnitt erklärt, fungiert OneLake als der zentrale Datenspeicher für verschiedene Datenobjekte in Fabric, darunter Lakehouses und Data Warehouses.
Weitere Informationen zu OneLake
Data Warehouse
Im Gegensatz zum SQL-Endpoint eines Lakehouse bietet ein Data Warehouse zusätzliche Unterstützung für Data Definition Language (DDL) und Data Manipulation Language (DML). In diesem Sinne handelt es sich um ein klassisches Enterprise Data Warehouse.

Weitere Informationen zu Data Warehouse
Delta Lake (Tables)
Die Tabellen im OneLake basieren auf dem Linux Foundation Delta Lake Format, welches üblicherweise in Apache Spark verwendet wird. Der Begriff "Delta Tables" bezeichnet Tabellen im Delta Lake Format. Als Speicherformat kommen versionierte Parquet-Files zum Einsatz, die durch ein Transaktionsprotokoll (Transaction Log) Time-Travel ermöglichen.
Lakehouse
Ein Lakehouse in Fabric vereint die Flexibilität und Skalierbarkeit eines Data Lake mit den Abfrage- und Analysemöglichkeiten eines Data Warehouse. Es stellt eine umfassende Sammlung von Daten, Dateien, Ordnern und Tabellen dar, die sowohl mit Apache Spark (z.B. PySpark) als auch mit SQL abgefragt werden können.
Jedes Lakehouse generiert drei Objekte im Workspace:

1. Lakehouse:
Das zentrale Repository, das Dateien, Ordner und Tabellen enthält und mit dem beispielsweise über Notebooks interagiert werden kann.

2. Semantic Model (Default) (früher Dataset (Default)):
Ein automatisch erstelltes, gemanagtes Datenset, das auf den Tabellen im Lakehouse basiert und in Power BI verwendet werden kann.
3. SQL Endpoint:
Ein Read-Only SQL-Endpoint, der es ermöglicht, klassische SQL-Abfragen direkt auf dem Lakehouse auszuführen.
Weitere Informationen zu Lakehouse
Copilot in Fabric: Ein neuer Weg, um Fabric-Objekte zu erstellen
An der Ignite 2023 wurden ebenfalls vielversprechende neue Möglichkeiten durch die Integration von Microsoft Copilot in Fabric angekündigt. Durch Copilot sollen Dataflows, Data Pipelines, Code, ML- Models oder Reports mittels natürlicher Sprache erstellt werden können:
"With Copilot in Microsoft Fabric, you can use natural language to create dataflows and pipelines, write SQL statements, build reports, or even develop machine learning models." (Quelle 1, Quelle 2, November 2023)
Die Preview von Copilot wird stufenweise ausgerollt. Das Ziel ist, dass Kunden mit einer Fabric F64 Kapazität oder höher sowie einer Power BI Premium P1 Kapazität oder höher bis Ende März 2024 Zugriff auf Copilot Preview haben (Microsoft Blogpost).
Fazit: Fabric bietet neue Möglichkeiten in der Datenverarbeitung
Fabric, Microsofts neueste SaaS-Lösung, hat seit ihrer allgemeinen Verfügbarkeit Mitte November eine breite Palette von Möglichkeiten für Data Engineering, Data Science, KI und Reporting eröffnet. Diese Plattform ermöglicht den Aufbau von Datenpipelines, die Aufbereitung von Daten für Reporting-Zwecke und die Durchführung von Data Science-Aktivitäten. Die Integration von Copilot klingt vielversprechend, allerdings ist noch nicht beurteilbar, wie nützlich die erzeugten Objekte in der Praxis sind.
Das Ziel war es, Ihnen Fabric mit diesem Beitrag kurz und verständlich zu erklären und Ihnen einen ersten Überblick zu verschaffen. Falls Sie mehr erfahren möchten oder Potenzial für Ihre Anforderungen sehen, stehen wir Ihnen gerne zur Verfügung.
Weiterführende Ressourcen
Ankündigung Fabric Microsoft Build 2023
Ankündigung Fabric Microsoft Ignite 2023
Microsoft Blog - Fabric GA Announcment
Microsoft Ignite 2023 - Book of News
Bildquelle: Microsoft




